2. Programming Model¶
2.1. Execution model¶
The most notable difference between OmpSs-2 and OpenMP is the absence of the parallel clause to specify where a parallel region starts and ends.
This clause is required in OpenMP since it uses the fork-join execution model, in which users must specify when parallelism starts and ends.
OmpSs-2 uses the model implemented by StarSs where parallelism is implicitly created when the application starts.
Parallel resources can be seen as a pool of threads–hence the name, thread-pool execution model–that the underlying run-time will use during the execution.
Warning
The user has no control over this pool of threads, so the standard OpenMP methods omp_get_num_threads() or its variants are not available to use.
At the beginning of the execution, the OmpSs-2 run-time system creates an initial pool of worker threads (i.e., there is no master thread in OmpSs-2). The main function is wrapped in an implicit task, which is called the main task, and it is added to the queue of ready tasks. Then, one of the worker threads gets that task from the queue, and it starts executing it. Meanwhile, the rest of threads wait for other ready tasks, which could be instantiated by the main task or other running tasks.
Multiple threads execute tasks that are defined implicitly or explicitly by annotating programs with OmpSs-2 directives. The OmpSs-2 programming model is intended to support programs that will execute correctly both as parallel and as sequential programs (if the OmpSs-2 language is ignored).
OmpSs-2 allows the expression of parallelism through tasks. Tasks are independent pieces of code that can be executed by parallel resources at run-time. Whenever the program flow reaches a section of code that has been declared as a task, instead of executing the task’s body code, the program will create an instance of the task and will delegate its execution to the OmpSs-2 run-time system. The OmpSs-2 run-time system will eventually execute the task on a parallel resource. The execution of these explicitly generated tasks is assigned to one of the worker threads in the pool of threads, subject to the thread’s availability to execute work. Thus, the execution of the new task could be immediate, or deferred until later according to task scheduling constraints and thread availability. Threads are allowed to suspend the current task region at a task scheduling point in order to execute a different task.
Any directive that defines a task or a series of tasks can also appear within a task definition. This allows the definition of multiple levels of parallelism. Defining multiple levels of parallelism can lead to a better performance of applications, since the underlying OmpSs-2 run-time system can exploit factors like data or temporal locality between tasks. Supporting multi-level parallelism is also required to allow the implementation of recursive algorithms.
The synchronization of tasks of an application is required in order to produce a correct execution, since usually some tasks depend on data computed by other tasks. The OmpSs programming model offers two ways of expressing this: data dependencies, and explicit directives to set synchronization points.
Regular OmpSs-2 applications are linked as whole OmpSs-2 applications, however, the run-time system also has a library mode.
In library mode, there is no implicit task for the main function.
Instead, the user code defines functions that contain regular OmpSs-2 code (i.e., tasks, …), and offloads them to the run-time system through an API.
In this case, the code is not linked as an OmpSs-2 application, but as a regular application that is linked to the run-time library.
2.2. Data sharing attributes¶
OmpSs-2 allows to specify the explicit data sharing attributes for the variables referenced in a construct body using the following clauses:
private(<list>)
firstprivate(<list>)
shared(<list>)
The private and firstprivate clauses declare one or more variables to be private to the construct (i.e., a new variable will be created).
All internal references to the original variable are replaced by references to this new variable.
Variables privatized using the private clause are uninitialized when the execution of the construct body begins.
Variables privatized using the firstprivate clause are initialized with the value of the corresponding original variable when the construct was encountered.
The shared clause declares one or more variables to be shared to the construct (i.e., the construct still will refer the original variable).
Programmers must ensure that shared variables do not reach the end of their lifetime before other constructs referencing them have finished.
There are a few exceptions in which the data sharing clauses can not be used on certain variables due to the nature of the symbol. In these cases we talk about pre-determined data sharing attributes and they are defined by the following rules:
Dynamic storage duration objects are shared (e.g.,
malloc,new, …).Static data members are shared.
Variables declared inside the construct body with static storage duration are shared.
Variables declared inside the construct body with automatic storage duration are private.
When the variable does not have a pre-determined behaviour and it is not referenced by any of the explicit data sharing rules it is considered to have an implicit data sharing attribute according to the following rules:
If the variable appears in a
dependclause, the variable will be shared.If a
defaultclause is present in the construct, the implicit data sharing attribute will be the one defined as a parameter of this clause.If no
defaultclause is present and the variable was private/local in the context encountering the construct, the variable will be firstprivate.If no
defaultclause is present and the variable was shared/global in the context encountering the construct, the variable will be shared.
The default(none) clause disables all implicit data sharing attributes of a construct, which forces the user to specify the data sharing attribute of each variable that appears inside the construct body.
2.3. Dependence model¶
Asynchronous parallelism is enabled in OmpSs-2 by the use of data-dependencies between the different tasks of the program. OmpSs-2 tasks commonly require data in order to do meaningful computation. Usually a task will use some input data to perform some operations and produce new results that can be later used by other tasks or parts of the program.
When an OmpSs-2 program is being executed, the underlying run-time system uses the data dependence information and the creation order of each task to perform dependence analysis. This analysis produces execution-order constraints between the different tasks which results in a correct order of execution for the application. We call these constraints task dependences.
Each time a new task is created its dependencies are matched against those of existing tasks. If a dependency, either Read-after-Write (RaW), Write-after-Write (WaW) or Write-after-Read(WaR), is found the task becomes a successor of the corresponding tasks. This process creates a task dependency graph at run-time. Tasks are scheduled for execution as soon as all their predecessors in the graph have finished (which does not mean they are executed immediately) or at creation if they have no predecessors.
In the general case, the statement that follows the pragma is to be executed asynchronously. Whenever a thread encounters a task construct, it instantiates the task and resumes its execution after the construct. The task instance can be executed either by that same thread at some other time or by another thread. The semantics can be altered through additional clauses and through the properties of the enclosing environment in which the task is instantiated.
Dependencies allow tasks to be scheduled after other tasks using the depend clause. They allow to specify for each task in the program what data a task is waiting for and signaling is readiness. Note that whether the task uses that data in the specified way is the responsibility of the programmer.
The depend clause admits the following keywords: in, out, inout, concurrent or commutative.
The keyword is followed by a colon and a comma-separated list of elements (memory references).
The syntax permitted to specify memory references is described in Language section.
The data references provided by these clauses are commonly named the data dependencies of the task.
The semantics of the depend clause are also extended with the in (standing for input), out (standing for output), inout (standing for input/output), concurrent and commutative clauses to this end.
All these clauses also admit a comma-separated list of elements (memory references) as described in the previous paragraph.
The meaning of each clause/keyword is explained below:
in(memory-reference-list): If a task has aninclause that evaluates to a given lvalue, then the task will not be eligible to run as long as a previously created sibling task with anout,inout,concurrentorcommutativeclause applying to the same lvalue has not finished its execution.out(memory-reference-list): If a task has anoutclause that evaluates to a given lvalue, then the task will not be eligible to run as long as a previously created sibling task with anin,out,inout,concurrentorcommutativeclause applying to the same lvalue has not finished its execution.inout(memory-reference-list): If a task has aninoutclause that evaluates to a given lvalue, then it is considered as if it had appeared in aninclause and in anoutclause. Thus, the semantics for theinandoutclauses apply.concurrent(memory-reference-list): Theconcurrentclause is a special version of theinoutclause where the dependencies are computed with respect toin,out,inoutandcommutativebut not with respect to other concurrent clauses. As it relaxes the synchronization between tasks users must ensure that either tasks can be executed concurrently or additional synchronization is used.commutative(memory-reference-list): If a task has a commutative clause that evaluates to a given lvalue, then the task will not become a member of the commutative task set for that lvalue as long as a previously created sibling task with anin,out,inoutorconcurrentclause applying to the same lvalue has not finished its execution. Given a non-empty commutative task set for a certain lvalue, any task of that set may be eligible to run, but just one at the same time. Thus, tasks that are members of the same commutative task set are executed keeping mutual exclusion among them.
The usual scope of the dependency calculation is restricted to that determined by the enclosing (possibly implicit) task. That is, the contents of the depend clause of two tasks can determine dependencies between them only if they share the same parent task. In this sense, tasks define an inner dependency domain into which to calculate the dependencies between its direct children. However, OmpSs-2 improves the combination of data dependencies and task nesting, as will be explained in the next sections.
The following example shows how to define tasks with task dependences:
void foo (int *a, int *b) {
for (int i = 1; i < N; i++) {
#pragma oss task in(a[i-1]) inout(a[i]) out(b[i])
propagate(&a[i-1], &a[i], &b[i]);
#pragma oss task in(b[i-1]) inout(b[i])
correct(&b[i-1], &b[i]);
}
}
This code generates at run-time the following task graph:
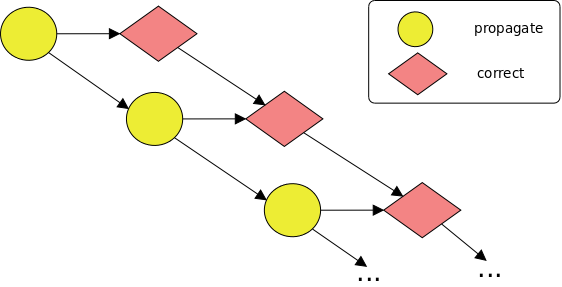
The following example shows how we can use the concurrent clause to parallelize a reduction over an array:
#include <stdio.h>
#define N 100
void reduce(int n, int *a, int *sum) {
for (int i = 0; i < n; i++) {
#pragma oss task concurrent(*sum)
{
#pragma oss atomic
*sum += a[i];
}
}
}
int main() {
int i, a[N];
for (i = 0; i < N; ++i)
a[i] = i + 1;
int sum = 0;
reduce(N, a, &sum);
#pragma oss task in(sum)
printf("The sum of all elements of 'a' is: %d\n", sum);
#pragma oss taskwait
return 0;
}
Note that all tasks that compute the sum of the values of a may be executed concurrently.
For this reason we have to protect with an atomic construct the access to the sum variable.
As soon as all of these tasks finish their execution, the task that prints the value of sum may be executed.
The following example shows how we can use the commutative clause:
#include <stdio.h>
int main() {
int a;
#pragma oss task out(a) // Task T1
a = 10;
#pragma oss task commutative(a) // Task T2
printf("Intermediate alue of 'a': %d\n", a++);
#pragma oss task commutative(a) // Task T3
printf("Intermediate value of 'a': %d\n", a++);
#pragma oss task in(a) // Task T4
printf("Final value of 'a' is: %d\n", a);
#pragma oss taskwait
return 0;
}
Note that the commutative tasks (T2 and T3) will be executed after the task that initializes a (T1), and before the task that prints the final value of a (T4).
No execution order of the commutative tasks is not guaranteed but they will not be executed at the same time by definition.
Thus, it is safe to modify the value of a inside those tasks.
2.3.1. Combining task nesting and dependencies¶
Being able to combine task nesting and dependences is important for programmability. The code below shows an example that combines nesting and dependencies with two levels of tasks. For brevity, the inner tasks do not have dependencies between their siblings.
#pragma oss task inout(a, b) // Task T1
{
a++; b++;
#pragma oss task inout(a) // Task T1.1
a += ...;
#pragma oss task inout(b) // Task T1.2
b += ...;
}
#pragma oss task in(a, b) out(z, c, d) // Task T2
{
z = ...;
#pragma oss task in(a) out(c) // Task T2.1
c = ... + a + ...;
#pragma oss task in(b) out(d) // Task T2.2
d = ... + b + ...;
}
#pragma oss task in(a, b, d) out(e, f) // Task T3
{
#pragma oss task in(a, d) out(e) // Task T3.1
e = ... + a + d + ...;
#pragma oss task in(b) out(f) // Task T3.2
f = ... + b + ...;
}
#pragma oss task in(c, d, e, f) // Task T4
{
#pragma oss task in(c, e) // Task T4.1
... = ... + c + e + ...;
#pragma oss task in(d, f) // Task T4.2
... = ... + d + f + ...;
}
#pragma oss taskwait
To parallelize the original code using a top-down approach we would perform the following steps.
First, we would add the pragmas of the outer tasks.
Since they have conflicting accesses over some variables, we add the corresponding dependency clauses (e.g., in and out) for each of their accessed variables.
In general, it is a good practice to have entries to protect all the accesses of a task.
Doing this reduces the burden on the programmer, improves the maintainability of the code and reduces the chances of overlooking conflicting accesses.
Then, inside each task, we identify separate functionalities and convert each into a task. If we follow the same approach, the depend clause of each inner task will contain entries to protect its own accesses.
When we consider how the depend clauses are composed, we observe that outer tasks contain a combination of elements to protect their own accesses and elements that are only needed by their subtasks. This is necessary to avoid data-races between subtasks with different parents. Note that parent tasks do not execute a taskwait at the end of their task body. Unlike OpenMP and OmpSs, OmpSs-2 automatically links the dependency domain of a task with that of its subtasks. Once a task finishes its execution, the dependencies that are not included in any of its unfinished subtasks are released. In contrast, the release of the dependencies that appear in any of its unfinished subtasks is delayed until these latter finish.
We strongly recommend avoiding taskwaits at the end of task bodies. Not only do they delay the finalization of tasks, but also hinder the discovery of parallelism. Moreover, taskwait delays the release of all dependencies until all subtasks finish, even the dependencies not declared by any subtask. Nevertheless, it is worth noting that the variables stored in the stack of the parent task are no longer valid once it returns from its task body. In the next section, we explain in detail the benefits of automatically linking dependency domains across task nesting levels without taskwaits.
2.3.2. Fine-grained release of dependencies across nesting levels¶
Detaching the taskwait at the end of a task from the task code allows the run-time system to be made aware earlier of the fact that the task code has finished and that it will not create further subtasks. In a scenario with task nesting and dependencies, this knowledge allows it to make assumptions about dependencies. Since the task code is finished, the task will no longer any action that may require the enforcement of its dependencies by itself. Only the dependencies needed by its live subtasks need to be preserved. In most cases, these dependencies are the ones associated with an element of the depend clause that also appears in a live subtask. Therefore, the dependencies that do not need to be enforced anymore could be released.
This incremental fine-grained release of dependencies is the default behaviour in OmpSs-2 tasks.
However, this behaviour can be disabled with the wait clause, which defers the release of all dependencies of a task until it has finished the execution of its body and all its subtasks deeply complete.
This clause emulates a taskwait-like operation immediately after exiting from the task code, but avoids the overhead and drawbacks of a taskwait.
Notice that this improvement is only possible once the run-time system is aware of the end of the code of a task.
However, it may also be desirable to trigger this mechanism earlier.
For instance, a task may use certain data only at the beginning and then perform other lengthy operations that delay the release of the dependencies associated with that data.
The release directive asserts that a task will no longer perform accesses that conflict with the contents of the associated depend clause.
The contents of the depend clause must be a subset of that of the task construct that is no longer referenced in the rest of the lifetime of the task and its future subtasks.
2.3.3. Weak dependences¶
Some of the elements of the depend clause may be needed by the task itself, others may be needed only by its subtasks, and others may be needed by both. The ones that are only needed for the subtasks only serve as a mechanism to link the outer domain of dependencies to the inner one. In this sense, allowing them to defer the execution of the task is unnecessary, since the task does not perform any conflicting accesses by itself.
The dependence model in OmpSs-2 has been extended to define the weak counterparts of in, out, inout and commutative dependences.
Their semantics are analogous to the ones without the weak prefix.
However, the weak variants indicate that the task does not perform by itself any action that requires the enforcement of the dependency.
Instead those actions can be performed by any of its deeply nested subtasks.
Any subtask that may directly perform those actions needs to include the element in its depend clause in the non-weak variant.
In turn, if the subtask delegates the action to a subtask, the element must appear in its depend clause using at least the weak variant.
Weak variants do not imply a direct dependency, and thus do not defer the execution of tasks. Their purpose is to serve as a linking point between the dependency domains of each nesting level. Until now, out of all the tasks with the same parent, the first one with a given element in its depends clause was assumed to not have any input dependency. However, this assumption is no longer true since the dependency domains are no longer isolated. Instead, if the parent has that same element with a weak dependency type, there may be a previous and unfinished task with a depend clause that has a dependency to it. If we calculated dependencies as if all types were non-weak, in such a case, the source of the dependency, if any, would be the source of the non-enforced dependency on its parent over the same element.
This change, combined with the fine-grained release of dependencies, merges the inner dependency domain of a task into that of its parent. Since this happens at every nesting level, the result is equivalent to an execution in which all tasks had been created in a single dependency domain.
2.3.4. Extended data dependencies expressions¶
All dependence clauses allow extended lvalues from those of C/C++. Two different extensions are allowed:
Array sections allow to refer to multiple elements of an array (or pointed data) in a single expression. There are two forms of array sections:
a[lower : upper]. In this case all elements of ‘a’ in the range of lower to upper (both included) are referenced. If no lower is specified it is assumed to be 0. If the array section is applied to an array and upper is omitted then it is assumed to be the last element of that dimension of the array.
a[lower; size]. In this case all elements of ‘a’ in the range of lower to lower+(size-1) (both included) are referenced.Shaping expressions allow to recast pointers into array types to recover the size of dimensions that could have been lost across function calls. A shaping expression is one or more
[size]expressions before a pointer.
Implementations may choose not to support the extended data dependencies model, in which case array sections and shaping expressions will register a single dependency to the first element of the specified range. For example, an expression of the form a[lower : upper] will be interpreted as a dependency over a[lower].
The following example shows examples of these extended expressions:
void sort(int n, int *a) {
if (n < small) seq_sort(n, a);
#pragma oss task inout(a[0:(n/2)-1]) // equivalent to inout(a[0;n/2])
sort(n/2, a);
#pragma oss task inout(a[n/2:n-1]) // equivalent to inout(a[n/2;n-(n/2)])
sort(n/2, &a[n/2]);
#pragma oss task inout(a[0:(n/2)-1], a[n/2:n-1])
merge (n/2, a, a, &a[n/2]);
#pragma oss taskwait
}
Note that these extensions are only for C/C++, since Fortran supports, natively, array sections. Fortran array sections are supported on any dependence clause as well.
2.3.5. Dependences on the taskwait construct¶
In addition to the dependencies mechanism, there is a way to set synchronization points in an OmpSs-2 application.
These points are defined using the taskwait directive.
When the control flow reaches a synchronization point, it waits until all previously created sibling tasks deeply complete.
OmpSs-2 also offers synchronization points that can wait until certain tasks are completed.
These synchronization points are defined by adding any kind of task dependence clause to the taskwait construct.
2.3.6. Multidependences¶
Multidependences is a powerful feature that allows defining a dynamic number of any kind of dependences. From a theoretical point of view, a multidependence consists of two different parts: first, an lvalue expression that contains some references to an identifier (the iterator) that doesn’t exist in the program and second, the definition of that identifier and its range of values. Depending on the base language the syntax is a bit different:
dependence-type({memory-reference-list, iterator-name = lower; size})for C/C++.
dependence-type([memory-reference-list, iterator-name = lower, size])for Fortran.
Additionally, a multidependence may specify the step of the range in the following way:
dependence-type({memory-reference-list, iterator-name = lower; size : step})for C/C++.
dependence-type([memory-reference-list, iterator-name = lower, size, step])for Fortran.
Despite having different syntax for C/C++ and Fortran, the semantics of this feature is the same for the 3 languages: the lvalue expression will be duplicated as many times as values the iterator have and all the references to the iterator will be replaced by its values.
The following code shows how to define a multidependence in C/C++:
void foo(int n, int *v)
{
// This dependence is equivalent to inout(v[0], v[1], ..., v[n-1])
#pragma oss task inout({v[i], i=0;n})
{
for (int j = 0; j < n; ++j)
v[j]++;
}
}
And a similar code in Fortran:
subroutine foo(n, v)
implicit none
integer :: n
integer :: v(n)
! This dependence is equivalent to inout(v[1], v[2], ..., v[n])
!$oss task inout([v(i), i=1, n])
v = v + 1
!$oss end task
end subroutine foo
2.4. Task scheduling¶
When the current executed task reaches a task scheduling point, the implementation may decide to switch from this task to another one from the set of eligible tasks. Task scheduling points may occur at the following locations:
In a task generating code.
In a taskwait directive.
Just after the completion of a task.
When entering or exiting a critical section.
When explicitly blocking or unblocking a task through the blocking API.
Switching the execution of a task to a different task if known as task switching and it may imply to begin the execution of a non-previously executed task or to resume the execution of a partially executed task. Task switching is restricted in the following situations:
The set of eligible tasks (at a given time) is initially formed by the set of tasks included in the ready task pool (at this time).
Once a task has been executed by a given thread, it can be only resumed by the very same thread (i.e., the set of eligible tasks for a thread does not include tasks that have been previously executed by a different thread).
When creating a task with the
ifclause for which expression evaluated to false, the run-time system must offer a mechanism to immediately execute this task (usually by the same thread that creates it).When executing in a
finalcontext all the encountered task generating codes will execute the task immediately after creating it as if it was a simple routine call (i.e., the set of eligible tasks in this situation is restricted to include only the newly generated task).
Note
Remember that the ready task pool does not include tasks with dependences still not fulfilled (i.e., not all predecessors of a task have finished yet) or blocked tasks in any other condition (e.g., tasks executing a taskwait with non-finished child tasks).
2.5. Conditional compilation¶
In implementations that support a preprocessor, the _OMPSS_2 macro name is defined to have a value.
In order to keep non OmpSs-2 programs still compiling programmers should use the symbol definition to guard all OmpSs-2 routine calls or any specific mechanism used by the OmpSs-2 programming model.
2.6. Runtime options¶
OmpSs-2 uses the run-time library routines to check and configure different Control Variables (CVs) during the program execution. These variables define certain aspects of the program and run-time behaviour. A set of shell environment variables may also be used to configure the CVs before executing the program.
A list of library routines can be found in chapter Library Routines from this specification. However, some library routines and environment variables are implementation defined and programmers will find them documented in the OmpSs-2 User Guide.