1. Introduction¶
OmpSs-2 is a programming model composed of a set of directives and library routines that can be used in conjunction with a high-level programming language to develop concurrent applications. This programming model is an effort to integrate features from the StarSs programming model family, developed by the Programming Models group of the Computer Sciences department at Barcelona Supercomputing Center (BSC), into a single programming model.
OmpSs-2 extends the tasking model of OmpSs/OpenMP to support both task nesting and fine-grained dependences across different nesting levels, which enables the effective parallelization of applications using a top-down methodology.
Tasks are the elementary unit of work which represents a specific instance of an executable code. Dependences let the user annotate the data flow of the program, this way at run-time this information can be used to determine if the parallel execution of two tasks may cause data races.
The goal of OmpSs-2 is to provide a productive environment to develop applications for modern High-Performance Computing (HPC) systems. Two concepts add to make OmpSs-2 a productive programming model: performance and ease of use. Programs developed in OmpSs-2 must be able to deliver a reasonable performance when compared to other programming models targeting the same architecture(s). Ease of use is a concept difficult to quantify but OmpSs-2 has been designed using principles that have been praised for their effectiveness in that area.
In particular, one of our most ambitious objectives is to extend the OpenMP programming model with new directives, clauses and/or API services or general features to better support asynchronous data-flow parallelism and heterogeneity. These are, currently, the most prominent features introduced in the OmpSs-2 programming model:
Lifetime of task data environment: A task is completed once the last statement of its body is executed. It becomes deeply completed when also all its children become deeply completed. The data environment of a task, which includes all the variables captured when the task is created, is preserved until the task is deeply completed. Notice that the stack of the thread that is executing the task is NOT part of the task data environment.
Nested dependency domain connection: Incoming dependences of a task propagate to its children as if the task did not exist. When a task finishes, its outgoing dependences are replaced by those generated by its children.
Early release of dependences: By default, once a task is completed it will release all the dependences that are not included on any unfinished descendant task. If the wait clause is specified in the task construct, all its dependences will be released at once when the task becomes deeply completed.
Weak dependences: The weakin/weakout clauses specify potential dependences only required by descendants tasks. These annotations do not delay the execution of the task.
Native offload API: A new asynchronous API to execute OmpSs-2 kernels on a specified set of CPUs from any kind of application, including Java, Python, R, etc.
Task Pause/Resume API: A new API that can be used to programmatically suspend and resume the execution of a task. It is currently used to improve the interoperability and performance of hybrid MPI and OmpSs-2 applications.
1.1. Reference implementation¶
Currently, there are two reference implementations of the OmpSs-2 programming model. One of the implementations is based on the Nanos6 runtime library and the LLVM/Clang compiler. The other implementation is based on the nOS-V and NODES runtimes and the LLVM/Clang compiler.
The LLVM/Clang compiler is an LLVM-based compiler that provides the necessary support for transforming high-level directives into a parallelized version of the application.
The Nanos6 runtime system library provides the services to manage all the parallelism in the user-application, including task creation, synchronization and data movement, and provide support for resource heterogeneity.
The nOS-V library is a threading and tasking runtime that supports co-execution and can be leveraged by higher-level programming models.
The NODES library is a runtime designed to work on top of the nOS-V runtime while providing most of the functionalities of its predecessor, Nanos6. It acts as a dependency system for nOS-V by synchronizing the data flow of OmpSs-2 codes.
Although Nanos6 is still maintained, its development has stopped. Thus, we recommend installing the reference implementation based on nOS-V and NODES.
1.2. A bit of history¶
OmpSs-2 is the second generation of the OmpSs programming model. The name stems from combining the names of two other programming models: OpenMP and StarSs. The design principles of these two programming models constitute the fundamental ideas used to conceive the OmpSs philosophy.
OmpSs takes from OpenMP its viewpoint of providing a way to, starting from a sequential program, produce its parallel version by introducing annotations in the source code. These annotations do not have an explicit effect on the semantics of the program. Instead, they allow the compiler to produce a parallel version of it. This feature allows users to parallelize applications incrementally. Starting from the sequential version, new directives can be added to specify the parallelism of different application parts. Consequentially, this positively impacts the productivity that can be achieved by this philosophy. Generally, when using more explicit programming models, applications need to be redesigned to shape them into their parallel versions, and the responsibility of these implementations is laid upon users. This translates to an increase in the maintenance effort of source codes, and tasks like debugging or testing become more complex.
StarSs, or Star SuperScalar, is a family of programming models that also offer implicit parallelism through a set of compiler annotations. It differs from OpenMP in some important aspects. StarSs uses the thread-pool execution model, while OpenMP implements fork-join parallelism. StarSs also includes features to target heterogeneous architectures through leveraging native kernel implementations while OpenMP targets accelerator support through direct compiler code generation. Furthermore, StarSs offers asynchronous parallelism as the main mechanism of expressing parallelism whereas OpenMP only started to implement it in its 3.0 version. Finally, StarSs offers task synchronization through dependences as the main mechanism of expressing the task execution order, enabling the look-ahead instantiation of tasks, whereas OpenMP started including this mechanism in its 4.0 version.
StarSs raises the bar on how much implicitness is offered by the programming model. When programming using OpenMP, the developer first has to define which regions of the program will be executed in parallel. Afterward, developers must express how the inner code is going to be executed by threads from the parallel region. Finally, it may be required to add directives to synchronize the different parts of the parallel execution. StarSs simplifies part of this process by providing an environment where parallelism is implicitly created from the beginning of the execution, thus the developer can omit the declaration of parallel regions. The definition of parallel code is leveraged through the concept of tasks, which are blocks of code that can execute asynchronously in parallel. To synchronize the parallelism of StarSs applications, the programming model also offers a dependency mechanism, which allows expressing the correct order in which individual tasks must be executed to guarantee a proper execution. This mechanism enables a much richer expression of parallelism than the one offered by OpenMP, and results in StarSs applications exploiting parallel resources more efficiently.
OmpSs tries to be the evolution that OpenMP needs in order to be able to target newer architectures. For this, OmpSs takes key features from OpenMP but also new ideas that have been developed in the StarSs family of programming models.
1.3. Influence in OpenMP¶
Many OmpSs and StarSs ideas have been introduced into the OpenMP programming model. The next figure summarizes our contributions in the standard:
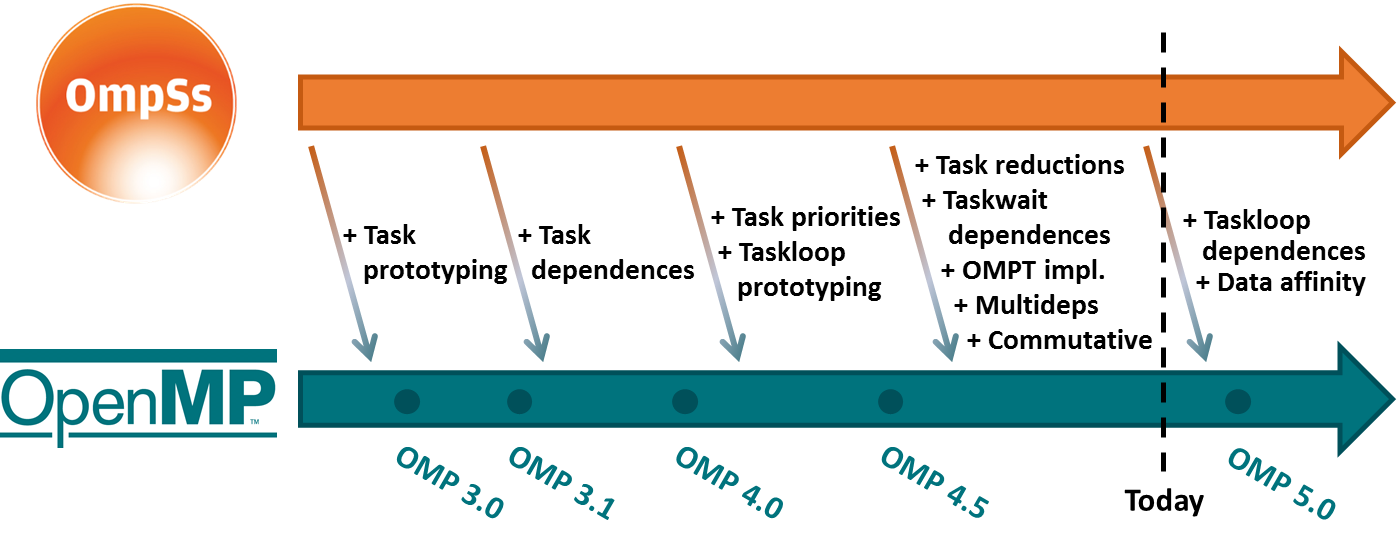
Starting from version 3.0, released on May 2008, OpenMP included support for asynchronous tasks. The reference implementation, which was used to measure the benefits that tasks provided to the programming model, was developed at BSC and consisted on the Nanos4 run-time library and the Mercurium source-to-source compiler.
Our next contribution, which was included in OpenMP 4.0 (released on July 2013), was the extension of the tasking model to support data dependences, one of the strongest points of OmpSs that allows to define fine-grain synchronization among tasks. This feature was tested using Mercurium source-to-source compiler and the Nanos++ RTL.
In OpenMP 4.5, released on November 2015, the tasking model was extended with the taskloop construct using Nanos++ as the reference implementation to validate these ideas.
BSC also contributed to version 4.5 adding the priority clause to task and taskloop constructs, and the Nanos++ RTL was used to validate the new interface included in the OpenMP standard with respect to third party tools.
OpenMP 5.0, released on November 2018, included several featured influenced by the OmpSs-2 programming model and implemented and tested through the Nanos6 runtime system:
task reductionsas a way to use tasks as the participants of a reduction operation.
iteratorsandmultidependencesmechanisms to specify a variable number of dependences for a task instance.
taskwait dependencesto relax the set of descendants to wait for before proceeding with the taskwait construct.
mutexinoutset, also known ascommutativein OmpSs-2, a new type of dependence to support mutually exclusive tasks.Detached tasks and data affinity support.
OpenMP 5.1, released on November 2020, included support for the concurrent clause and taskloop dependences.
OpenMP 6.0, released on November 2024, included support for free-agent threads, taskcaching, and transparent tasks (also known as weakdependences in OmpSs-2).
1.4. Glossary of terms¶
- ancestor tasks¶
The set of tasks formed by a parent task and all its ancestors.
- base language¶
The base language is the programming language in which the program is written.
- child task¶
A task is another task’s child when the latter encounters its task generating code.
- construct¶
A construct is an executable directive and its associated statement. Unlike the OpenMP terminology, we explicitly refer to the lexical scope of a construct or the dynamic extent of a construct when needed.
- data environment¶
The data environment of a task is formed by its associated set of variables.
- declarative directive¶
A directive that annotates a declarative statement.
- dependence¶
The relationship existing between a predecessor task and one of its successor tasks.
- descendant tasks¶
The descendant tasks of a given task are a set of all its child tasks and their descendants.
- directive¶
In C/C++ a #pragma preprocessor entity.
In Fortran a comment which follows a given syntax.
- dynamic extent¶
A dynamic extent is the interval between establishing an execution entity and its explicit disestablishment. Dynamic extents always obey a stack-like discipline while running the code, and include any code in called routines as well as any implicit code introduced by the OmpSs-2 implementation.
- executable directive¶
A directive that annotates an executable statement.
- expression¶
A combination of one or more data components and operators that the base program language may understand.
- function task¶
In C, a task declared by a
taskdirective at file-scope that comes before a declaration that declares a single function or comes before a function-definition. In both cases the declarator should include a parameter type list.In C++, a task declared by a
taskdirective at namespace-scope or class-scope that comes before a function-definition or comes before a declaration or member-declaration that declares a single function.In Fortran, a task declared by a
taskdirective that comes before a theSUBROUTINEstatement of an external-subprogram, internal-subprogram or an interface-body.- inline task¶
In C/C++ an explicit task created by a
taskdirective in a statement inside a function-definition.In Fortran, an explicit task created by a
taskdirective in the executable part of a program unit.- lexical scope¶
The lexical scope is the portion of code which is lexically (i.e. textually) contained within the establishing construct including any implicit code lexically introduced by the OmpSs-2 implementation. The lexical scope does not include any code in called routines.
- outline tasks¶
An outlined task is also know as a function task.
- predecessor task¶
A task becomes predecessor of another task when there are dependences between both (i.e. its successor tasks). In other words, there is a restriction in the order the runtime system must execute them: all predecessor tasks must complete before a successor task can be executed.
- parent task¶
A task encountering another task’s generating code is its parent task.
- ready task pool¶
The set of tasks ready to be executed (i.e. they are not blocked by any condition).
- structured block¶
An executable statement with a single entry point (at the top) and a single exit point (at the bottom).
- successor task¶
A task becomes successor of another task when there are dependences between them (i.e. its predecessor task and itself). In other words, there is a restriction in the order the runtime system must execute them: all predecessor tasks must complete before a successor task can be executed.
- task¶
A task is the minimum execution entity that can be managed independently by the runtime scheduler (although a single task may be executed at different phases according to its task scheduling points). Tasks in OmpSs-2 can be created by any task generating code.
- task dependency graph¶
The set of tasks and its relationships (successor / predecessor) with respect to the correspondant scheduling restrictions.
- task generating code¶
The code which creates a new task upon being executed. In OmpSs-2, it can occur when encountering a
taskconstruct, aloopconstruct or when calling a routine annotated with ataskdeclarative directive.- task scheduling point¶
The different points in which the runtime system may suspend the execution of the current task and execute a different one.