3.2.3. Accelerator interconnect options¶
Simplified interconnect¶
By default, memory interconnection is implemented as 2 interconnection stages:
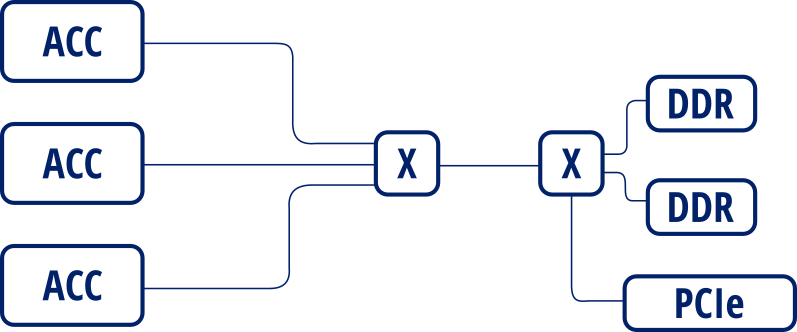
2 stage interconnection¶
This is done in order to save resources in the case that there’s data access ports. However, this serializes data accesses. This prevents accelerators from accessing different memory banks in parallel.
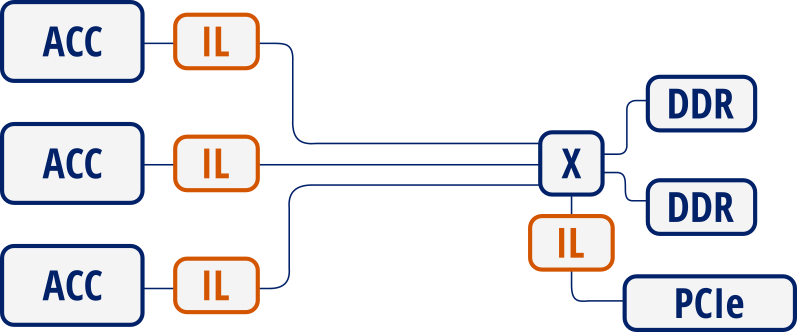
By setting the --simplify_interconnection will result in the following:

Simplified interconnection¶
When also setting --interconnect_opt=performance can allow accelerators
to concurrently access different banks, effectively increasing overall available bandwidth.
Otherwise, accesses will not be performed in parallel as the interconnect is configured
in “area” mode.
However, the downside is that this can affect timing and resource usage when this interconnection mode is enabled.
Memory access interleave¶
By default, FPGA memory is allocated sequentially.
By setting the --memory_interleaving_stride=<stride> option will result
in allocations being placed in different modules each stride bytes.
Therefore accelerator memory accesses will be scattered across the different memory interfaces.
For instance, setting --memory_interleaving_stride=4096.
Will result in the first 4k being allocated to bank 0,
next 4k are allocated info bank 1, and so on.
This may improve accelerator memory access bandwidth when combined with Simplified interconnect and Interconnect optimization strategy options:
Simplified interconnection with memory interleaving¶
Interconnect optimization strategy¶
Option --interconnect_opt=<optimization strategy> defines the optimization strategy
for AXI interconnects.
This option only accepts area or performance strategies.
While area results in lower resource usage,
performance is lower than the performance setting.
In particular, using area prevents access from different slaves into different masters do be performed in parallel. This is specially relevant when using Simplified interconnect.
See also Xilinx PG059 for more details on the different strategies.
Interconnect register slices¶
By specifying --interconnect_regslice=<interconnect group> option,
it enables outer and auto register slice mode on selected interconnect cores.
This mode places an extra outer register between the inner interconnect logic (crossbar, width converter, etc.) and the outer core slave interfaces. It also places an auto register slice if the slave interface is in the same clock domain. See Xilinx PG059 for details on these modes.
Interconnect groups are defined as follows:
all: enables them on all interconnects.mem: enables them on interconnects in memory data path (accelerator - DDR)hwruntime: enables them on the AXI-stream interconnects between the hwruntime and the accelerators (accelerator control)
Interface debug¶
Interfaces can be set up for debugging through ILA cores. By setting debugging options, different buses will be set up for debugging and the corresponding ILA cores are generated as needed.
There are two modes to set up debugging, By enabling debug in interface group
through --debug_intf=<interface group> or selecting individual interfaces using
--debug_intf_list=<interface list files>.
Interface group selection¶
Interfaces can be marked for debug in different groups specified in the
--debug_intf=<interface group>:
AXI: Debug accelerator’s AXI 4 memory mapped data interfaces interfacesstream: Debug accelerator’s AXI-Stream control interfacesboth: Debug bothAXIandstreaminterface groups.custom: Debug user-defined interfacesnone: Do not mark for debug any interface (this is the default behaviour)
Interface list¶
Al list of interfaces can be specified in order to enable individual interfaces
through the --debug_intf_list=<interface list files> option.
Interface list contains a list of interface paths, one for each line.
Interface paths are block design connection paths.
Ait creates an interface list with all accelerator data interfaces named
<project name>.datainterfaces.txt.
First column is the slave end (origin) of the connection
and second column specifies the master (destination) end.
Accelerator data interfaces are specified as
<accelerator>_<0>/<accelerator>_ompss/<interface name>
For instance to debug interface x and y from accelerator foo
interface list should look as follows:
/foo_0/foo_ompss/m_axi_mcxx_x
/foo_0/foo_ompss/m_axi_mcxx_y