DLB is a library devoted to speed up hybrid parallel applications and maximize the utilization of computational resources since 2009.
- It is a dynamic library transparent to the user
- No need to analyze nor modify the application
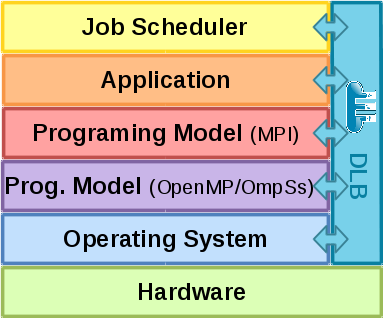
- Transversal to the different layers of the HPC software stack (see fig. 1)
- Maximizes the utilization of computational resources
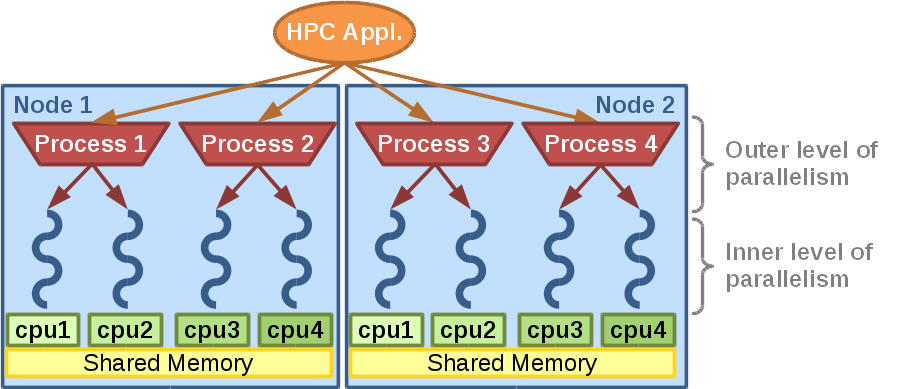
- Improves the load balance of hybrid applications (see fig. 2)
- Manages the number of threads in the shared memory level
- Compatible with MPI, OpenMP and OmpSs. (We are open to adding support for more programming models in both inner and outer level of parallelism.)
- Since version 3.0 DLB includes three independent and complementary modules:
- LeWI: Lend When Idle
- DROM: Dynamic Resource Ownership Management
- TALP: Tracking Application Live Performance
LeWI: Lend When Idle
This module aims at optimizing the performance of hybrid applications without a previous analysis or modifying the code.
LeWI will improve the load balance of the outer level of parallelism by redistributing the computational resources at the inner level of parallelism. This readjustment of resources will be done dynamically at runtime.
This dynamism allows DLB to react to different sources of imbalance: Algorithm, data, hardware architecture and resource availability among others.
The DLB approach to redistributing the computational resource at runtime depending on the instantaneous demand can improve the performance in different situations:
- Hybrid applications with an imbalance problem at the outer level of parallelism
- Hybrid applications with an imbalance problem at the inner level of parallelism
- Hybrid applications with serialized parts of the code
- Multiple applications with different parallelism patterns
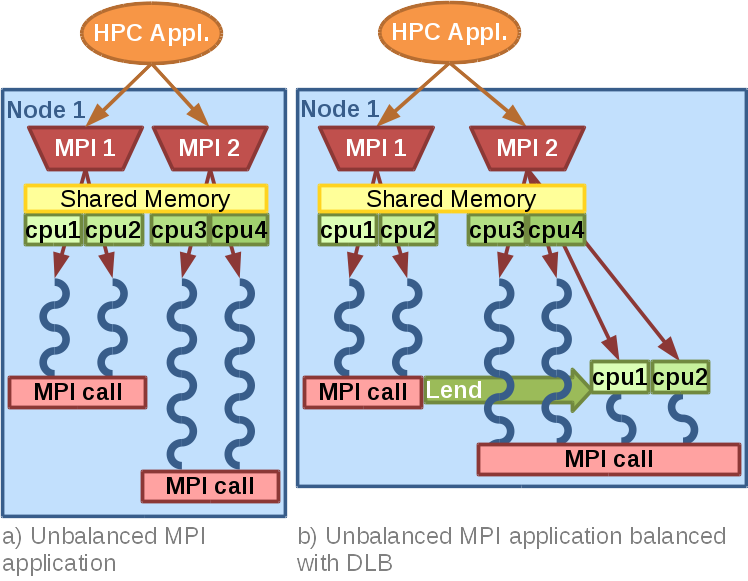
In fig. 3 we can see an example of LeWI. In this case, the application is running two MPI processes in a computing node, with two OpenMP threads each one. When MPI process 1 reaches a blocking MPI call it will lend its assigned cpus (number 1 and 2) to the second MPI process running in the same node. This will allow MPI process 2 to finish its computation faster.
DROM: Dynamic Resource Ownership Management
This module allows reassigning computational resources from one process to another depending on the demand.
DROM offers and API that can be used by an external entity, ie. Job Scheduler, Resource Manager…
With the DROM API a CPU can be removed from a running application and given to another one:
- To a new application to allow collocation of applications
- To an existing application to speedup its execution
TALP: Tracking Application Live Performance
TALP is a lightweight, portable, extensible, and scalable tool for online parallel performance measurement. The efficiency metrics reported by TALP allow HPC users to evaluate the parallel efficiency of their executions, both post-mortem and at runtime.
The API that TALP provides allows the running application or resource managers to collect performance metrics at runtime. This enables the opportunity to adapt the execution based on the metrics collected dynamically. The set of metrics collected by TALP are well defined, independent of the tool, and consolidated.
Contact Information
- Marta Garcia. marta.garcia [at] bsc.es
- Victor Lopez. victor.lopez [at] bsc.es
Downloads and User Guide
The DLB source code is distributed under the terms of the LGPL-3.0 and can be downloaded here. You can also visit our github page.
The DLB user guide is available online here.
A DLB tutorial can be downloaded here.
Publications
To cite DLB
- Hints to improve automatic load balancing with LeWI for hybrid applications
at Journal of Parallel and Distributed Computing 2014.
(bibtex) (pdf)
More details on DLB
-
LeWI: A Runtime Balancing Algorithm for Nested Parallelism
at International Conference in Parallel Processing 2009, ICPP09.
(bibtex) (pdf) -
DROM: Enabling Efficient and Effortless Malleability for Resource Managers
at 47th International Conference on Parallel Processing, August 2018.
(bibtex) (pdf) -
TALP: A Lightweight Tool to Unveil Parallel Efficiency of Large-scale Executions
at Performance EngineeRing, Modelling, Analysis, and VisualizatiOn STrategy, June 2021.
(bibtex) (pdf)
Other DLB related publications
-
Computational Fluid and Particle Dynamics Simulations for Respiratory System: Runtime Optimization on an Arm Cluster
at 47th International Conference on Parallel Processing, August 2018.
(bibtex) (pdf) -
High-Performance Computing: Dos and Don’ts
at Computational Fluid Dynamics-Basic Instruments and Applications in Science, Intech February 2018.
(bibtex) (pdf) -
DJSB: Dynamic Job Scheduling Benchmark
at Workshop on Job Scheduling Strategies for Parallel Processing 2017.
(bibtex) (pdf) -
Dynamic Load Balancing for Hybrid Applications
PhD Thesis Marta Garcia-Gasulla, April 2017.
(pdf) (tdx) -
Dynamic load balance applied to particle transport in fluids
at International Journal of Computational Fluid Dynamics 2016.
(bibtex) -
Experience with the MPI/STARSS programming model on a large production code
at Advances in Parallel Computing 2014. -
A Dynamic Load Balancing approach with SMPSuperscalar and MPI
at Facing the Multicore Challenge II 2011.
(bibtex) (pdf)